

Mark Otto and bootstrap
For any that don’t know the domain, Mark Otto is the creator and an active participant of Bootstrap. The framework that changed the look of the internet. Bootstrap is one of the largest Github repositories on the internet. It has alot of contributors. I chose Mark Otto simply because he’s a web developer celebrity. I recognize that extremely meaningful contributions have been made by many other developers out there, and I’m in no way trying to diminish their work and effort.
Mining Op.
All my source code can be found in my Github repo. I used Python, Pandas, Numpy, Matplotlib, NLTK, Jupyter and datasets gathered from Github logs.
Purpose
I wanted to explore Natural Language Processing techniques. I used the very popular Natural Language ToolKit. The folks behind this project did a great job. I like using it and the documentation is superb!
Dataset
I mined my own data from scratch. I sifted over more than a decade of git logs. I imported all the logs into two columns: “Date” and “Comment.” Then, I split the data into four different sets. One for each version of Bootstrap, v2-v5. v5 isn’t out yet, so it’s a great time to mine the data since we can make some predictions or, get some insights as to what is expected with the official release.
NLTK
I created a corpus of all the comments of each data set. A corpus is essentially a big document of words. I stripped the corpus of all the common stop words. These are all the non-essential words in a sentence such as, “is” or “are.” Next, I looked at the top 20 most frequent words. I added to the “stop words” list some words that I thought weren’t helpful. Words that were domain specific like; “merge”, “pull” and “request.”
Then, I removed all punctuation from the sentences. Otherwise, I ended up with “:” and “,” as the most common items reported in my plots. Clearly, this isn’t useful for my purposes.
Finally, I used NLTK to stem all the words. This is a process linguists use to find the root of a word. For example, Mark Otto says “fix” a lot in his comments. However, sometimes he says “fixes” and “fixed,” and even “fixing.” When you’re looking for the frequency of a word, you’d have to look for all of those alterations of the word in order to get an actual representation of how often he is fixing something. When stemming the words, they’re iteratively broken down into their constituent root form. In this example it’d be “fix.”
Word Cloud
I found a nice easy to use project on Github that creates a cool little word cloud. Word clouds are a fun visual way to digest information. It’s hard for me to believe sometimes, however not everyone wants to stare are plots and charts. The project can be found on Github by: Andreas Mueller.
The Plots
All the datasets I created are all the comments leading up to the official release of the specific version of Bootstrap. Version 2 was released back in January of 2012, all these comments were prior to January 31st 2012.
I’ve include a true linguistic frequency and what I called a count plot for each version. NLTK has a function FreqDist which computes the number of times a word is used. However, I wanted to see how often that word was used compared to the rest of the words or, frequency normalized. Naturally, I’m not going to do this myself. Hell, that’s half the reason I use Python so that I can build upon what others have accomplished. I found this handy function by: Martina Pugliese.
Bootstrap v2
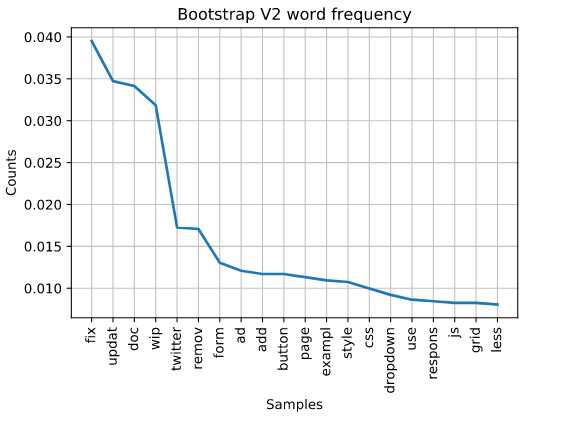
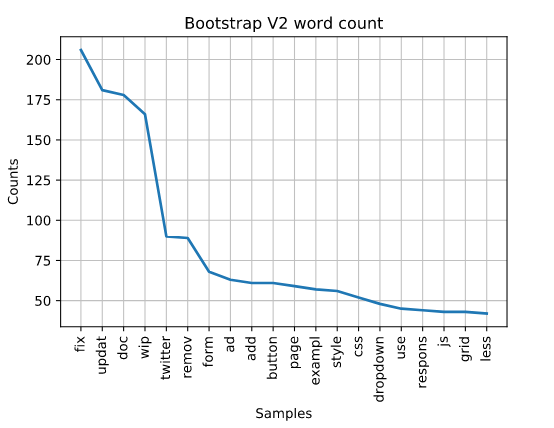
Perhaps the most interesting version, because the top word “fix” appears at a frequency of nearly 4%. The second most common word is update. Due to the stemming we get what is frequently called over stemming. Some of the words get trimmed a bit too much, but this doesn’t really diminish the readability.
Compared to the others it seems that Mark worked on a lot of updates, twitter integration and page features. The Twitter word makes sense. Twitter experienced rapid growth around 2007-2010 and even released a new website. Therefore, it makes sense that we’d see a lot of comments centered around Twitter integration leading up to v2, which was released in 2012. This was also the first official version to support “responsive web design” techniques. Which can be noticed by the keyword towards the end “respons.”
Bootstrap v3
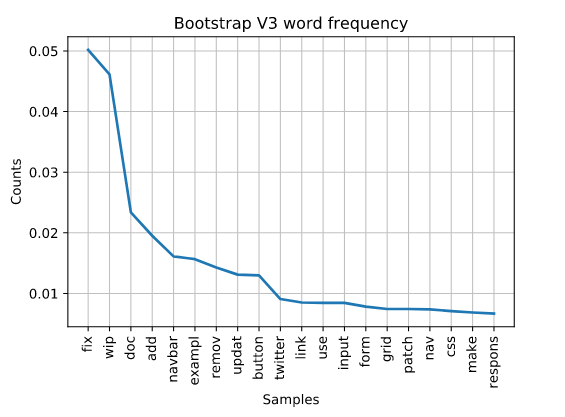
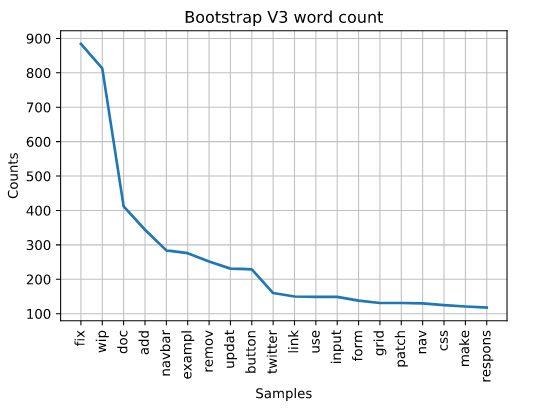
Now let’s look at the next version of Bootstrap, which was released on August 19, 2013. “Fix” is still the top word. No surprise there. We see “navbar” appear for the first time. V2 and v3 it would seem were similar for Mark because he was working on a lot of “wips” since this is also in the top words, whereas they don’t even appear in later versions by him. Perhaps, he was still working heavily on developing new features.
Bootstrap v4
V4 was officially released January 18, 2018. One of the top words that should be noticed is “grunt”. Well, if you know your JavaScript tool chain history, which I most certainly did not, Grunt is a tool used to help developers with the JavaScript build process. Grunt was officially released in January of 2012. It would make sense that we start seeing comments pop up regarding it after v3 of Bootstrap.
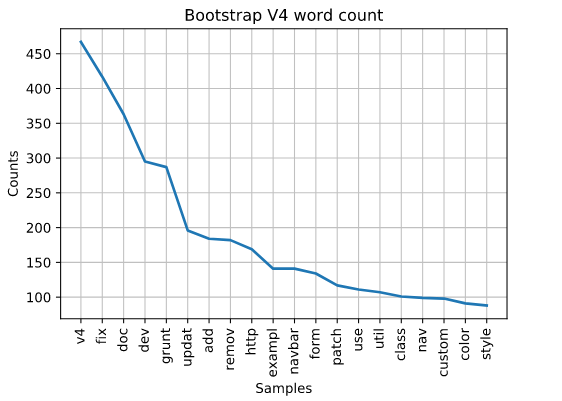
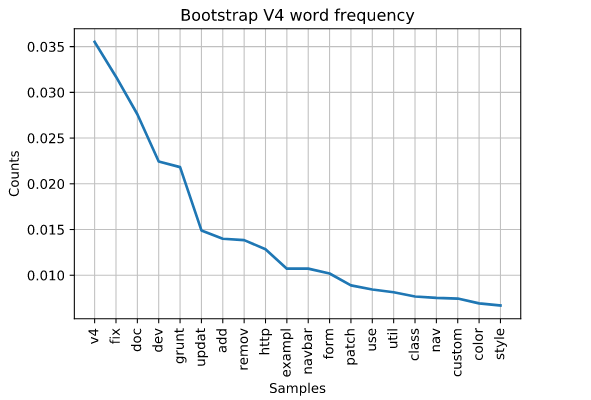
Less work on fixing
Mark, it seems, is working less on fixing related items as the versions get later. We see in v2 his frequency of the word “fix” is at 4% and then in v3 it’s at an all time high of 5%. Then, we see it decline to less than 3.5% for v4 and what we have of the v5 release.
The future of Bootstrap
Thus far, it seems Mark is working on a lot of documentation. V4 is still pretty high on the list so perhaps he’s still working on v4. However, we can also see http is at the end of the list. Does this mean we’ll be getting some new http api features? Also, the word “new” pops up for the first time.
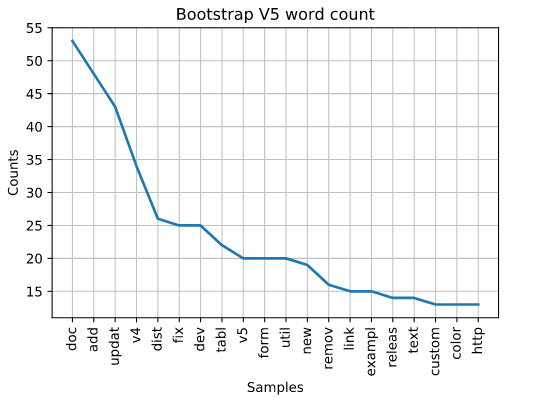
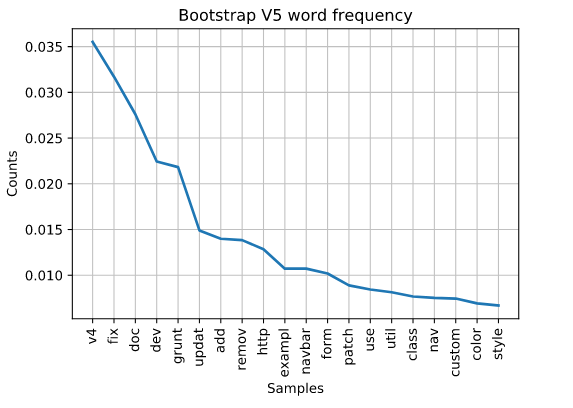
But, the most we can really glean from this, is that it would appear Mark is still working extensively on features associated with v4. Not surprising since he was working extensively on v3 and then got pulled away to help with the v4 release. It appears the same thing might be happening again.
Wrap up
Either way, I’m sure Mark and all the lovely developers working on Bootstrap will continue to impress the rest of use. I’m so thankful for all the developers that work on this project. Without it my websites would look horrendous. Thanks for all the help Bootstrap developers! Thanks for the data Mark.
Sources
Banner and thumbnail taken from Mike Bear
 Copy Link
Copy Link